lsof to find large open files
Was having a space allocation problem with a ceph host and couldn’t figure out what was holding files open.. finally listed lsof by size
lsof | grep REG | awk '{ print $1,$7,$9 }' | sort -t ' ' -k 2 -V
Found rsyslog had huge files open
splunkd REG 16400942226 splunkd REG 16400942226 splunkd REG 16400942226 splunkd REG 16400942226 rsyslogd REG 164487529796 rsyslogd REG 164487529796
heartbeat_map is_healthy ‘MDSRank’ had timed out after 15
Your cluster on fire? MDS won’t start?
Set the beacon grace GLOBALLY or MON AND MDS.
ceph config set mon mds_beacon_grace 360
ceph config set mds mds_beacon_grace 360
Ceph Optimal Recovery Values
The Ceph defaults for this are a little too aggressive for most devices, this will give you a more reasonable recovery speed that does not tank the system as hard but still yields a quick stable recovery.
ceph config set osd osd_recovery_sleep_hdd 0.25
ceph config set osd osd_recovery_sleep_ssd 0.05
ceph config set osd osd_recovery_sleep_hybrid 0.10Ceph – Delete erasure coded pgs after dataloss
Sometimes you have failures that cannot be fixed… ie EC 2+1 and 2 drives failing… (btw this was the recommended default EC profile of 14.x..) and you should use 8+3 at minimum to prevent this!
Warning, everything below ensures data loss on the affected PG.
ceph pg PGID query | jq .acting # Stop OSD related to PG, figure out the shard id of the pg, generally its .s0, .s1, .s2 depending on your EC config. ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0/ --pgid PGID.s1/2 --force --op remove # Restart the osd, wait for it to attempt to peer, stop it then mark it complete. ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0/ --pgid PGID.s1/2 --op mark-complete # Tell the customer your mistake is acceptable.. ceph pg 13.df mark_unfound_lost delete
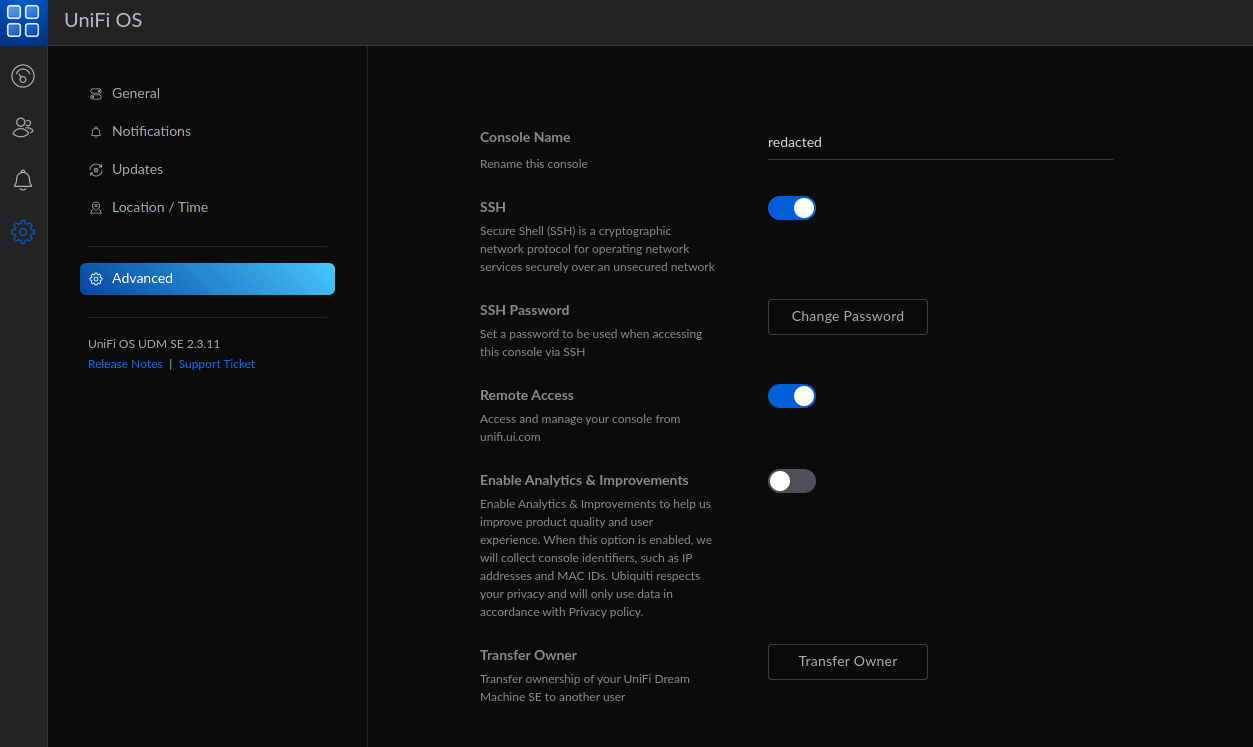
Unifi UDM ssh access for UDM and Unifi Switches / Access Points and adopted devices
This GUI isn’t super intuitive but heres where to click to dig down in and find your settings.
UDM
UDM > Settings (Bottom of sidebar menu) > Advanced > SSH
Unifi Switch
UDM > Network > Settings (Bottom of sidebar menu) > System > Application Configuration > Device SSH Authentication.

Installing Headless Nvidia Drivers in Ubuntu 20.04 and up
Lots of poor documentation around the interwebs for this… here is the required packages to make this useful. If you want the normal driver with xorg just remove headless from the package name.
apt install linux-headers-$(uname -r) -y
apt install nvidia-headless-470-server nvidia-utils-470-server libnvidia-encode-470-server -y2015-2019 GT350 Engine Assembly Manual PDF
This took forever to find, saving here for others.
How does video encoding work? MP4? I-Frames?! P-Frames!?!?! GOP!!!?!?!!?
This is a placeholder for me comprehending how video encoding works… I’ll update/edit as I become more familiar.. please don’t assume I have any idea what im talking about.
But, basically you have a GOP (group of pictures) and that GOP has a specified number of frames per second. So lets say you have a 30 FPS video, it has 30 frames per second of data, you can have a number of GOP that is different than that though.
So lets say you have a GOP size of 90, but your frame rate is 30 FPS. You will then have 29 P-Frames per I-Frame, For a total of 87 P-frames and 3 I-Frames.
I-Frames are ENTIRE picture, P-Frames are the “guess” at what changed since the last I-Frame. More I-Frames = more bandwidth.
https://en.wikipedia.org/wiki/Video_compression_picture_types
Oh Wowza
https://www.wowza.com/docs/how-to-encode-source-video-for-wowza-streaming-cloud#configure
https://ipvm.com/reports/test-i-frame-rate
https://www.axis.com/files/whitepaper/wp_bit_rate_66275_en_1512_hi.pdf
Watch frames in realtime
ffprobe -rtsp_transport tcp -i rtsp://root:[email protected]:554/axis-media/media.amp?streamprofile=ayet -show_frames | grep -E 'pict_type=I|coded_picture_number'